What I did at Khan Academy
For the past four months, I’ve been working with the incredible team at Khan Academy to get Khan Academy Computer Science shipped and (mostly) stable. In that time. I’ve been working remotely from Toronto, which has been an interesting experience, but that’s the topic of a future post.
I’m just going to use this post as a massive braindump for everything I worked on so I can share some knowledge, give some examples of the breadth and depth that interns at Khan Academy have the opportunity to work at, and so that I can remember where all the time went. I also spent a large amount of time refactoring everything I wrote and doing code reviews, but that’s not much fun to brag about.
This is going to be a long one, so feel free to scroll until something catches your eye.
Computer Science
My primary focus of the term was the new Computer Science curriculum. John Resig had been working on it for a long time before I arrived, but he needed a couple extra pairs of hands and eyes to get it shipped. As one of three developers working on Computer Science, I ended up being all over the place, but here are some of the features I had ownership over.
Backend

I’ve been responsible for creating and modifying the python backend for Computer
Science since the beginning of my internship. We’re using Google App
Engine’s db.Model for all the models (one day to be
ndb.Model), webapp2 for routing all the pages, Flask for the
API, and Jinja2 for the server-side templates.
The webapp2 handlers generally only serve HTML, possibly with some model data bootstrapped into the page. All of the creating, updating and deleting is done via the API from the client-side.
I also wrote a whole bunch of functional and access tests for the API.
(Functional tests answering the question “Can I do what I’m supposed to?” and
access tests answering the question “Am I restricted from doing what I’m not
allowed to?“).
Number Scrubber
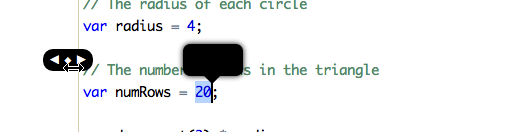
The mechanism for messing around with numbers in the editor was originally just a jQuery UI slider. The slider felt wrong because it had a hard minimum and maximum cap despite there being no logical general minimum or maximum for numbers in code.
What I really wanted was something closer to to the scrubber described by Bret Victor in his Scrubbing Calculator (the first demo).
The original version of the scrubber that replaced the slider used the x-axis to control the base value and the y-axis to control the power of ten used as a multiplier. Each horizontal “band” of 50 pixels represented a different power of ten.
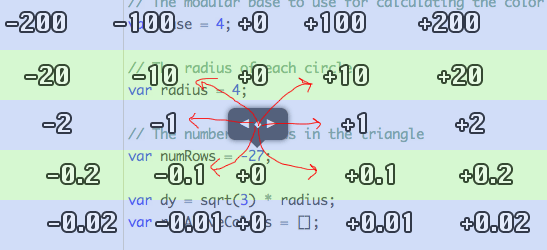
So if you wanted to increase or decrease at an interval of 100, you would drag left and right within the band 75 to 125 pixels above the number. If you wanted to increase/decrease at an interval of 0.1, you would drag left and right 25 in the band to 75 pixels below the number. Of course, you didn’t need to know the exact pixel numbers – you would just move your mouse up and down until it did what you wanted. It worked something like the image above.
While in theory this was extremely flexible and beautiful, in testing it out with kids at the Discovery Lab, it was apparent that it was confusing and not intuitive, so it was scrapped. Right now, the interval the scrubber runs on is always 1.
I have a diff awaiting review that restores some of the usefulness in (what I hope is) a more intuitive way. Instead of controlling the magnitude by the position of the mouse while dragging, the magnitude is controlled by the number of decimal places in the original number. The table below summarizes how that works.
number | interval
---------+----------
0.01 | 0.01
0.91 | 0.01
1.01 | 0.01
0.90 | 0.01
1.0 | 0.1
1 | 1
1000 | 1
1000.0 | 0.1
-1.01 | 0.01
Canvas Screenshots
Since one of the main points of the new Computer Science curriculum was that pictures are more engaging and motivating than text, it seemed really silly that our list of tutorials was a big wall of text. To fix that, we wanted to have every program display with a thumbnail of what the canvas looked like when you hit “Save”.
The basics of this turned out to be relatively straightforward. The canvas API
exposes a method toDataURL, which I use like so:
var imgDataUrl = myCanvas.toDataURL('image/png');
This returns a base-64 encoded data: URL containing a png. It might look
something like this:
data:image/png;base64,iVBORw0KGgoAAAANSUhEUgA...
In the initial version of this, I just took that data:image/png URL and
crammed it directly into the image src of the page, which worked! There were
two major disadvantages to this approach though: the base-64 encoded version of
binary data is significantly larger than the original binary data, and no
caching.
To solve both of these problems, I decoded the base-64 data on demand into a png, then set up caching headers to make Google App Engine’s Edge Caching servers cache the data as long as possible. The python code to do that inside a webapp2 handler looks like this:
base64_image_data = image_url[len("data:image/png;base64,"):]
self.response.headers['Content-Type'] = 'image/png'
self.response.headers['Cache-Control'] = 'public, max-age=1000000'
self.response.headers['Pragma'] = 'Public'
self.response.out.write(base64.b64decode(base64_image_data))
It turns out the headers that make Edge Caching kick in need to be pretty specific. You can read more about them here: https://groups.google.com/forum/#!msg/google-appengine/6xAV2Q5x8AU/QI26C0ofvhwJ
Content
My very, very first task was actually to create some proof of concept content using the editor to mimic some of Vi Hart’s Doodles. These were a lot of fun to work on, and they didn’t take very long. You can see all the ones I created to meet that end in Programs tagged with Vi Hart. Many of them have since been made much more aesthetically pleasing by fellow intern Jessica Liu, who voices all the tutorials at the moment.
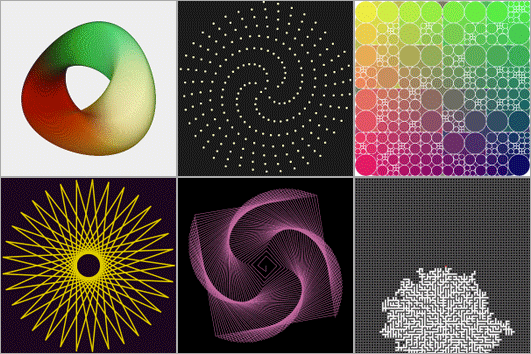
From left to right, top to bottom, these are a bunch of the programs I wrote that show up on under All Programs on Khan Academy.
Production Import
In an effort to provide adequate test data when working locally, I wrote a script to import all of the official Khan Academy programs to my local environment to make sure everything is working alright. This works by hitting an API handler on the production server, parsing the data, and inserting a bunch of records into the local datastore.
I wanted to make it so that I could import regularly without manually having to clean up the last import first, but I didn’t want to add a property to every single program record in production. Instead, I generate a user to own all of the programs imported from production, then simply delete all programs owned by that user in the script before the next import is performed. This lets me run the script and know that I have the latest copy of things on production without having duplicates.
Discussions
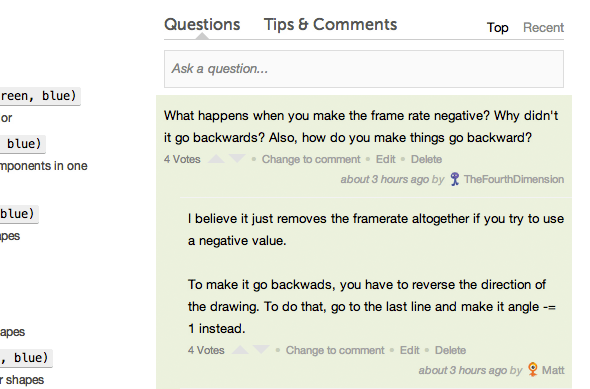
The last major feature I worked on before launch was getting discussions running on programs. The discussions system was originally designed to only work for videos, so this was a messy endeavour. With some vim-fu, I got this hammered out in 3 days, then spent the next 2 days fixing bugs found in production.
The crux of the problem was replacing every instance of “video” in the
discussions code with a polymorphic abstraction which I called the discussion
“focus” that could refer to either a video or a program. I initially just made
it so that “focus” was either a Video instance or a Scratchpad instance
(Scratchpad is the internal name for programs, since they underwent several
name changes in the UI, from “Scratchpad” to “Exploration” to “CodeCanvas”,
finally ending up as “Program”).
I shipped this change, but it quickly became apparent that this was hideously
fragile and resulted in duck typing of the worst kind. If someone was trying to
change something with the discussions on videos and forgot about programs during
their testing, there was likely to be a failure outside of what they were
testing. These problems are really difficult to catch in automated testing too,
because the error might happen on the clientside, when some data that’s assumed
to be there is just not in the JSON passed down at all, so it’ll fail silently
as undefined.
To fix this problem, I wrapped the model acting as the “focus” with an
intermediate layer with a strict interface. To do this, I created an abstract
class using python’s built-in library abc and made a class which
subclasses abc.AbstractBaseClass. This way, if someone wants to add some
functionality for videos, it will be extremely apparent to them that there are
other places that need updating. Because of the nature of abc, it’ll also
likely result in unit test failures instead of silent failures, since any
subclass of DiscussionFocus that doesn’t fully implement the interface will
throw an exception upon instantiation.
Khan Academy Tools and Infrastructure
Outside of the Computer Science stuff, I put in a couple of features and fixes for internal tooling and infrastructure.
Devshell
One of the gripes I’ve had with most of the web frameworks I’ve used since
building in Rails at The Working Group is how comparatively crummy the
developer tools are. One of the things I missed most was rails console. It
spins up a ruby REPL with the entire environment already loaded. This means I
can access models in the DB and make requests as if they were hitting a server.
This was an indispensable tool for testing and debugging.
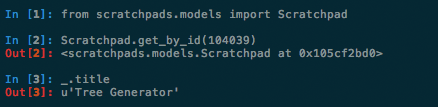
To my delight, one of my coworkers, Desmond Brand, had already written such a tool to use with Google App Engine. Near the beginning of the term, our entire system was upgraded from Python 2.5 to 2.7, which meant we could use IPython.
I took the idea behind what Desmond had written and rewrote it to use IPython
instead, resulting in a development REPL that would give me real DB access. I
called it devshell.py. Eventually, I was even able to make it work with
production data, allowing us to do similar things to the remote console on
Heroku.
Unfortunately, the system that powers devshell.py is too entangled in our
codebase at the moment to make open sourcing it simple, but here are the basic
steps that you need to go through:
- Programmatically find the path to the GAE SDK, and add that to
sys.path.
This will allow you to import things from thegooglenamespace in the REPL.
def _discover_sdk_path():
"""Return directory from $PATH where the Google Appengine DSK lives."""
# adapted from {http://code.google.com/p/bcannon/source/browse/
# sites/py3ksupport-hrd/run_tests.py}
# Poor-man's `which` command.
for path in os.environ['PATH'].split(':'):
if os.path.isdir(path) and 'dev_appserver.py' in os.listdir(path):
break
else:
raise RuntimeError("couldn't find appcfg.py on $PATH")
# Find out where App Engine lives so we can import it.
app_engine_path = os.path.join(os.path.dirname(path), 'google_appengine')
if not os.path.isdir(app_engine_path):
raise RuntimeError('%s is not a directory' % app_engine_path)
return app_engine_path
sys.path.append(_discover_sdk_path())
- Programmatically find the root of your GAE project, and add THAT to
sys.path. This will let you import your models to play around with.
def _project_rootdir():
appengine_root = os.path.dirname(__file__)
while True: # do while loop
if os.path.exists(os.path.join(appengine_root, 'app.yaml')):
return appengine_root
old_appengine_root = appengine_root
appengine_root = os.path.dirname(appengine_root)
if appengine_root == old_appengine_root:
# we're at and haven't found app.yaml
raise IOError('Unable to find app.yaml above cwd: %s'
% os.path.dirname(__file__))
sys.path.append(_project_rootdir())
- Get datastore access using
remote_api_stub.ConfigureRemoteApi. This is what will let you fetch and mutate models in the datastore in the REPL.
This requires that you have a runningdev_appserver.py.
from google.appengine.ext.remote_api import remote_api_stub
remote_api_stub.ConfigureRemoteApi(
None,
'/_ah/remote_api',
auth_func=lambda: ('test', 'test')
servername="localhost:8080")
- Embed IPython.
import IPython
IPython.embed()
Once all that’s done, you hopefully have a working IPython REPL for local development. Enjoy!
XSS Fix
All over the site, we have JSON embedded into the site used to bootstrap data into pages so they don’t have to immediately fire an AJAX request before being able to display anything. This is a really common strategy, but it’s unfortunately subject to a frustrating XSS vulnerability.
While we of course escape any user input in templates before we render them, usually having raw HTML strings in JSON is fine, and sometimes useful. When we’re rendering user content in client-side template with Handlebars, the output is escaped anyway. So we’re safe, right? Wrong.
The one case where HTML strings in embedded JSON cause problems is when they
contain </script>. Here’s an example of a template that’s vulnerable to this
problem.
<script>
var page = {{json.dumps(page)}};
</script>
Normally, something like {"body": "<h1>Awesome Page</h1>"} gets passed in, and
we have no problem. We get this as a result:
<script>
var page = {"body": "<h1>Awesome Page</h1>"};
</script>
And this is totally fine – no security problem. The problem comes around when
you inject </script> because it ends the script immediately, even though it
might be in the middle of a string. So if
{"body": "</script><script>alert('pwned - greetz to KA');</script>"}
gets sent to the template, the resulting page will have an alert on it. But
WAIT, you might say, why not just escape any HTML that gets put into the JSON
dump? Because then it’s subject to double escaping, and nobody wants to see
< on the page. Instead, to fix this, I patched the JSON encoder we use (we
don’t use json.dumps directly for other reasons) to replace every occurrence
of </ with <\/. Which seems to fix the problem, since <\/script> won’t
break in the middle of script tags. This doesn’t disrupt existing behaviour,
because '/' and '\/' are identical in JavaScript.
Blog Posts
Here’s a conversation I had with Ben Kamens, Khan Academy’s lead developer, near the beginning of my internship.
Me: hey - what's the policy on blogging during work hours? (I'm a lot more
aware of "work hours" now that I'm clocking my working hours)
Him: encouraged
Him: assuming it's remotely relevant :)
Me: cool :P
Him: if it's a blog about ice cream sandwiches, then it's only encouraged
for 4 hours a day instead of 8
As a result, I got to take the time to write a bunch of blog posts I never would’ve had the time to write during my free time (including this one!).
- An Argument for Mutable Local History in which I argue for amending and rebasing and generally whine about merge commits.
- My Mercurial Setup and Workflow at Khan Academy in which I describe in rambling detail how I get code into the repository.
- Khan Academy Computer Science: Instant Gratification and Bragging Rights in which I explain how my love of stacking plastic bricks led me to help create Khan Academy’s Computer Science platform.
In general, I try to write at least one blog post a month, but I’ve been missing that goal a lot during previous work terms and during school. This post makes 4 posts in 4 months, which hasn’t happened in a while.
Open Source
I also had the opportunity to contribute to a fairly sizable open source project and release two small ones of my own.
arcanist
Arcanist is the commandline component of Phabricator, which Khan Academy partially adopted at the beginning of my internship as a new code review tool. I had used it extensively while I was working at Facebook during a previous internship, and I found the mercurial support lacking.
So I opened my vim, hacked away, then hopped on IRC in #phabricator and got my
pull requests on github merged (Evan Priestley is amazing). My main contribution
is supporting a mutable history workflow for mercurial that was previously only
available in git. This should eventually lead to near parity with Phabricator’s
git support. The only major component still missing is the ability to use arc
land.
You can see my contributions to the project on github: jlfwong’s commits on facebook/arcanist.
vim-arcanist
I <3 vim and I <3 the functionality introduced in arc inlines, so I
thought I’d try my hand at writing a vim plugin to combine them.
arc inlines lists all of the inline comments for the current associated
Differential revision.
:ArcInlines takes that list and shoves it into the quickfix buffer for quick
navigation with :cnext and :cprev.
The result looks something like this:
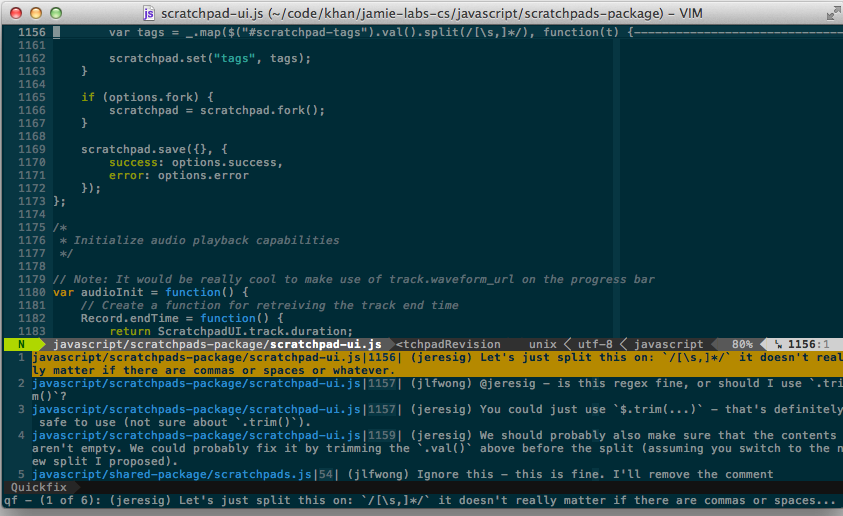
There’s more information in the README in vim-arcanist on GitHub.
This was my first reasonably polished vim plugin, but more importantly, this is the first project I’ve tried to promote and document with pictures and a screencast. I learned that screencasting can be a frustrating endeavour and that making GIFs is time consuming.
vim-mercenary
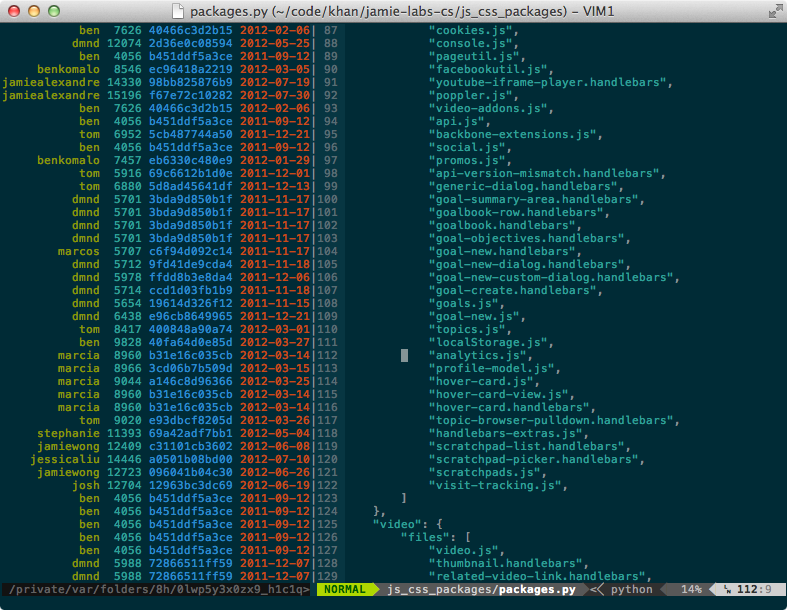
vim-mercenary is a mercurial wrapper for vim that allows you to make some
mercurial commands more useful by augmenting them with vim’s capabilities. The
image above shows :HGblame, which annotates the current file with the blame
and locks the scrolling of the two windows together.
There are more screenshots and a bunch of documentation in the README in vim-mercenary on GitHub.
The plugin was heavily inspired by Tim Pope’s git wrapper for vim, vim-fugitive. Originally, I was hoping to just hack vim-fugitive to repurpose it for mercurial, but eventually discovered that the architectures of hg and git are too different for it to be feasible. I did spend a lot of time reading through the source of vim-fugitive for inspiration on how to tackle the problem though.
The result is a fairly limited feature set, taking only the parts I found most useful and easiest to implement from vim-fugitive and sticking them into vim-mercenary.