The JavaScript Packaging Problem
I’ve been working on making Khan Academy’s JavaScript safer and faster since I joined as a full time software engineer back in July.
There’s a lot of ground to cover, so let’s ignore module systems, minification, code maintainability, and just focus on the problem of delivery performance.
Here’s the problem definition: you have a whole bunch of JavaScript that you want people to download on your website. How do you get said JavaScript from your server to your users’ browsers? Your goal is to get this to happen as fast as possible.
Here’s the setup: you have a website with a whole bunch of pages. There is some amount of JavaScript shared by all of those pages, some more that’s shared by some of those pages, and some that’s only used on one of those pages.
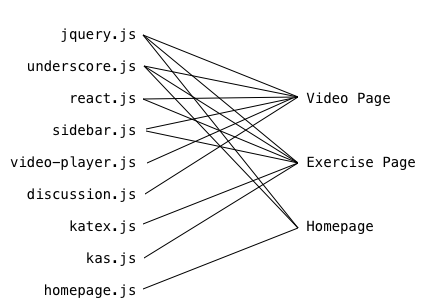
For the sake of discussion, let’s use an incredibly simplified version of Khan Academy: there are video pages, exercise pages, and a home page.
Here’s a breakdown of which JavaScript source files are needed on each page:
Solution 1: One Script Tag Per Source File
The easiest and most obvious solution looks like this:
<!doctype html>
<html>
<head>
<title>Video Page</title>
</head>
<body>
<!-- Server rendered video page content goes here ... ->
<script src="/js/jquery.js"><script>
<script src="/js/underscore.js"></script>
<script src="/js/react.js"></script>
<script src="/js/sidebar.js"></script>
<script src="/js/video-player.js"></script>
<script src="/js/discussion.js"></script>
</body>
</html>
And then on the homepage, you’d have:
<script src="/js/jquery.js"><script>
<script src="/js/underscore.js"></script>
<script src="/js/homepage.js"></script>
This is by far the simplest solution because it requires no fancy build system
like Grunt or gulp - you can just serve your JS directly from disk.
You’re going to want to have a build step anyway to do minification though, so
this isn’t a huge advantage.
Cache Performance
On the upside, this solution gives excellent cache performance. Each one of the files can be separately cached, so changing one of your JS files will require users to download only the things that changed since the last time they were there1. This is especially attractive because the biggest files, like jQuery, are unlikely to change frequently.
Even better, if you need different JS files on different pages on your site, you
only have to download the bits of that page that you didn’t already get from
visiting other pages. For instance, if you went from the homepage to the video
page, you’d already have jquery.js and underscore.js in your cache.
Network Performance
On the major downside, this is a ton of network traffic. If you have 10 JS script files on your page, then you’re firing 10 HTTP requests to get those 10 files from server to browser. Each of these has overhead, and requires a round trip to the server. Establishing connections can be slow, and each connection undergoes TCP Slow-start, meaning that it doesn’t reach full speed until after a few round trips2. Downloading ten 20kB files is a great deal slower than downloading one 200kB file over HTTP because of this.
These problems are largely mitigated by SPDY, and support for SPDY is rising, but it’s not good enough yet (about 75% as of this post) that we can just completely ignore problems in HTTP.
Compression
When you’re sending any plaintext assets (HTML, JS, CSS, etc.) from the server, you should be compressing those assets to send fewer bytes over the network. gzip is the normal solution. By serving each file separately from the server, we’re losing out on potential compression benefits.
As a test, I compared gzipping 60 JS files from one of Khan Academy’s folders and then concatenating the results vs. concatenating and gzipping after.
Concatenate then compress: ~82kB
$ cat *.js | gzip -c | wc -c
84015
Compress then concatenate: ~98kB
$ for i in *.js; do gzip -c $i; done | wc -c
99997
Summary of One Script Tag Per Source File:
- Downloads only what is needed
- High cache hit rate between page types
- High cache hit rate between deploys
- Many HTTP round trips
- Poor Compression
Solution 2: One Big JS File
When you see poor compression and the many HTTP round trips problems, the next most obvious thing might be to concatenate absolutely all of your JS together. Diagramatically, this would look like this:
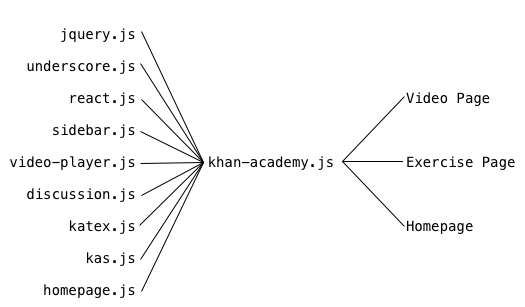
And then every single one of your HTML files would have this:
<script src="/build/js/khan-academy.js"></script>
While this does offer better compression and fewer HTTP round trips, we have two new problems. The first is that we’re now downloading potentially WAY more stuff on a page than we actually need.
For instance, to load up the homepage of the site, you now need to download all
of the source of react.js and video-player.js even though the homepage uses
none of that!
This problem gets worse as the number of pages you have goes up, especially if some of the infrequently visited pages depend on a ton of JavaScript.
The second problem is that your cache hit rate between deploys drops to zero.
Since everything is in one big file now, if you make a 1 line change to some
homepage.js and deploy, everyone has to re-download all of jquery.js,
video-player.js and everything else.
On the upside of cache performance, once you hit one page and download the stuff you need, as you switch to a different page, you already have all the JS you need cached in your browser.
Summary of One Big JavaScript File:
- Perfect cache hit rate between page types
- One HTTP round trip
- Excellent compression
- Forces users to download a lot of things they don’t need
- Zero cache hit rate between deploys
Solution 3: One JS File Per Page
Since downloading the entire site’s JS in one shot downloads way too much stuff, why don’t we just download one file that contains all the things we need on a per-page basis? That would look like this:
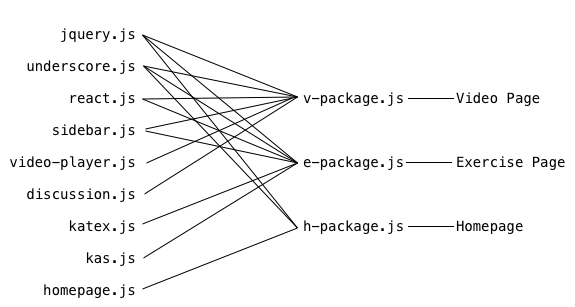
Then the homepage HTML would have:
<script src="/build/js/h-package.js"></script>
And the video page would have:
<script src="/build/js/v-package.js"></script>
This solution fixes the “downloading stuff we don’t need” problem, and also
improves cache performance between deploys. It’s much better than the “one big
file” solution because if you change homepage.js and deploy, your users won’t
need to re-download v-package.js or e-package.js since their contents
haven’t changed. You do still have to redownload all of h-package.js however,
which is sort of a bummer, because it means redownloading the big files like
jquery.js and react.js.
The worse problem is that your cache hit rate betwen pages is zero. Even though
every page uses jquery.js, it’s concatenated into each -package.js file, so
your browser has no idea that it might have it already. This means your browser
will download up to 3 copies of jquery.js: one in each of h-package.js,
v-package.js, and e-package.js.
Summary of One JavaScript File Per Page:
- Downloads only what is needed
- One HTTP round trip per page
- Good compression
- Coarse caching between deploys
- Zero cache hit rate between page types
Solution 4: Many Concatenated JS Files Per Page
As with many things in life, the solution is a compromise. We can’t get all of the benefits of all of the above solutions with none of the problems, but we can get rid of the worst problems to get something pretty good.
To provide finer-grained caching and improve cache hit rate between page types without massively inflating the number of HTTP connections, we go for something between “one script tag per file” and “one file per page”, and end up with this:
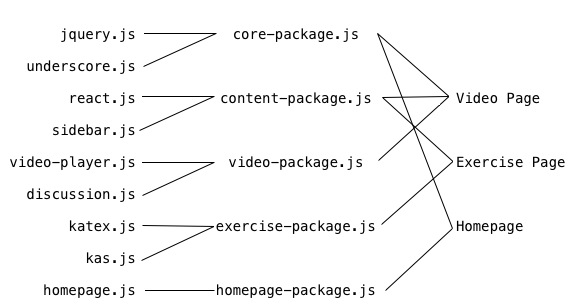
Once you have a system like this, you can try to balance all of the pros and
cons discussed in previous solutions. The above diagram shows a solution where
each page downloads only exactly what it needs, which is good, but you’ll notice
that react.js and sidebar.js are packaged together. react.js is pretty
big, so ideally I’d like to be able to change sidebar.js without forcing my
users to redownload react.js. I also might want to further minimize the number
of requests on the video and exercises page, and arrive at this:
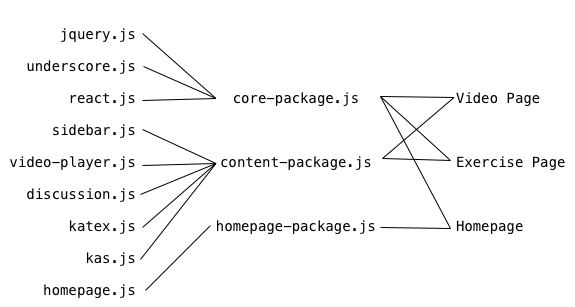
So now we have fewer requests, and we won’t break the cache on react.js by
changing something in sidebar.js, but we’re now downloading react.js on the
homepage, and downloading exercise-specific things that we don’t need on the
video page and vice versa.
So of these two packaging policies is better? The answer is (unsurprisingly)
that it depends. How likely is sidebar.js to change? How much compression
benefit do we get from putting jquery.js and react.js in the same
concatenated file?
Khan Academy has been using a variant of Solution 4 since before my first internship there in 2012, so my job is now mostly concerned with how to optimize our packages3.
Optimal Packaging?
The problem now comes down to two things: which .js files do I concatenate
together into each -package.js, and which -package.js files do I load from
each HTML page4?
Ultimately the goal is to minimize the average time the user spends between receiving the HTML response from the server and when enough JS runs so that they can do the thing they want to do on the page.
Even if you had those timings, turning that into actionable modifications to your file concatenation/package loading policy would be pretty difficult. A more pragmatic approach is to just have hitcounts for each different HTML page.
Once you have hitcounts for each HTML page, and you know the set of source JS files (“source” as in “before concatenation”), you can try to figure out how to move source files between packages in order to reduce the total aggregate number of bytes users are downloading in a given day5.
At Khan Academy, we’re just now delving into how to do automatic optimization of our packages, so we don’t have production-proven results to justify which metrics and algorithms to use to perform these optimizations, but I’ll be sure to report back when we do.
Existing Tools
For reasons I won’t go into in this post, Khan Academy uses our own in-house system for both packaging and specifying inter-file dependencies, but plenty of good open source tools exist that allow you to control how your files get concatenated together.
The three most battle tested I’m aware of:
- webpack with CommonsChunkPlugin would be my personal choice for a
new project. webpack tries to be unopinionated and pragmatic, supporting both
synchronous node style
require()and AMD style. It’s being used in production at Instragram. Pete Hunt has a guide up on how it’s used in production at Instagram: webpack-howto - Browserify with factor-bundle. Browserify uses node style
require(), and factor-bundle is the bit that lets you pull out common portions to be loaded separately. - RequireJS with the RequireJS Optimizer. There’s a specific example for optimizing for multi-page apps: example-multipage.
- Failure to properly cache bust static resources can lead to bugs where users are running a version of your JS from a previous deploy because they have it cached in their browser. Overly aggressive cache busting (e.g. busting everything on every deploy) forces users to download things they already have. A good solution is to hash all of your static assets when you upload them and include that hash in the filename. That way, users only download things that actually did change since the last time they visited the website.
[return] - While browsers will re-use TCP connections to make multiple HTTP requests, they still open multiple TCP connections when you request many resources to allow downloading things in parallel. Within a single connection, downloading one big resource will block the download of a smaller resource because the requests on a connection are entirely serialized. SPDY solves this problem by allowing multiple streams across a single TCP connection. [return]
- Before I can do that though, I need to know when it’s safe to move a file between packages, which requires us to have a reliable dependency graph between source files, which has been the bulk of the actual work I’ve done to date since working on the Computer Science Platform. [return]
- There’s also the question of how we load those packages (inline script tags, script with
srcattributes, dynamically JS injected script tags, or AJAX). This is a good watch if you have the time: Enough with the JavaScript Already by Nicholas Zakas. [return] - Interestingly, this is a variant of the weighted set cover problem, except we also control the elements of the sets! [return]